
L’été dernier, nous vous invitions pour la première fois à la découverte des membres de la Chaire, qui ne cesse de monter en puissance. Eh oui, ces trois dernières années ont été riches de multiples façons : projets, évènements, talks, conférences, recherches, etc. Alors, qui dit nouvel été dit nouveaux entretiens avec celles et ceux qui font vivre la Chaire !

Aujourd’hui, c’est Victor qui nous fait le plaisir de répondre à quelques questions.
Victor, pour commencer, peux-tu nous dire quelques mots sur ton parcours, sur les expériences professionnelles qui ont précédé ton arrivée à Nantes Université ?
Oui bien sûr, j’ai un parcours universitaire un peu singulier. 🙂
Pour commencer, j’ai obtenu mon Bac S en 2010 à Sète. Ensuite, j’ai fait pendant deux ans un DUT de Génie Civil en Corrèze, que j’ai obtenu en 2012. Suite à ce DUT, je pensais rentrer dans la vie active, mais le domaine des travaux publics ne correspondait pas vraiment à mes attentes. À cette époque, je n’avais jamais codé de ma vie. Après 6 mois dans le domaine, j’ai commencé une licence en travaillant en parallèle comme brancardier de nuit à l’hôpital de Sète. Je suis de ceux qui ont beaucoup bénéficié de la flexibilité de l’université publique. Au fur et à mesure de la licence, je me suis réorienté, pour finalement valider une licence informatique à l’Université de Montpellier. J’ai notamment passé ma troisième année de licence en échange à l’Université de Trois-Rivières au Québec et je suis, depuis, un fervent défenseur des programmes d’échanges.
Cela nous amène en 2016, et c’est le début du grand essor de l’Intelligence Artificielle, pour laquelle je me fascine, notamment grâce à de très bons contenus de vulgarisation comme les chaînes YouTube 3blue1brown, Science4all ou encore Two Minute Papers. J’en profite ici pour souligner le travail, à mon avis essentiel, réalisé par les vulgarisateurs.
Je commence alors le master IA et reconnaissance des formes de l’Université de Toulouse. En dernière année de master, je suis amené à réaliser un stage et je m’oriente naturellement vers la recherche. J’ai la chance alors de réaliser un stage extrêmement intéressant au LIUM (Laboratoire Informatique de l’Université du Maine au Mans), encadré par Nicolas Dugué. Le sujet du stage était à mi-chemin entre le domaine des complex networks (systèmes complexes) et celui du Traitement du Langage Naturel.
Suite à ce stage, je décide de candidater à une thèse à Nantes Université, portant sur les systèmes de recommandation appliqués à un contexte pédagogique. J’ai choisi cette thèse, car elle s’inscrit parfaitement dans la ligne de l’Objectif de Développement Durable n°4 UNESCO “Une éducation ouverte et de qualité pour tous”.
Cela fait maintenant 4 années que tu travailles au sein de Nantes Université. Comment et dans quel contexte s’est déroulée ta rencontre avec Colin, qui est aujourd’hui ton encadrant de thèse ?
Ma rencontre avec Colin s’est déroulée pour la première fois au téléphone, j’étais à la recherche d’un sujet de thèse à impact social positif. Et j’ai trouvé le sujet proposé par Colin et Hoël sur une liste de diffusion (bull-i3, que je recommande à tous ceux qui cherchent des thèses dans le domaine de l’informatique). J’ai alors candidaté et Colin m’a rappelé pour un entretien téléphonique. J’ai donc commencé ma thèse sans avoir jamais rencontré mon directeur de thèse (heureusement, je suis bien tombé 🙂 ).
Peux-tu nous en dire plus, justement, sur ta thèse ? Par exemple son sujet, ta problématique, les enjeux liés, tes expérimentations, etc. ?
Oui bien sûr. Ma thèse concerne la problématique de la recommandation de ressources éducatives dans un contexte d’apprentissage non-formel. Ce que cela veut dire, c’est que l’on souhaiterait être capable de recommander des ressources éducatives (comme Youtube recommande des vidéos), mais en axant la recommandation réalisée sur l’aspect pédagogique. L’idée ici n’est pas de recommander pour un objectif commercial, comme c’est souvent le cas. La différence fondamentale du contexte pédagogique, c’est que nous ne pouvons pas facilement définir un objectif mathématique à maximiser.
À titre d’exemples et pour vulgariser : dans les applications de e-business (par exemple Amazon), on cherche à maximiser le taux de conversion, c’est-à-dire le nombre de fois où un produit recommandé est acheté ; dans les applications de streaming (par exemple Youtube), on cherche à maximiser le temps de visionnage d’un contenu recommandé (et des pubs qui vont avec). Dans ces deux cas, l’objectif découle du modèle économique. Dans le cas d’un contexte pédagogique, on voudrait maximiser l’expérience d’apprentissage de l’apprenant. Mais comment l’approximer ?
Un des principaux verrous pour résoudre cette tâche concerne le manque de jeux de données publics. Je me suis donc employé à la fois à rendre des jeux de données publics et à développer une méthode permettant d’anonymiser les traces d’apprentissage afin de les rendre publiques.
Lorsque tu as commencé à travailler pour la Chaire, quels étaient les projets auxquels tu contribuais ?
Je travaillais en particulier sur le projet X5-GON. L’idée du projet était de créer un grand index des RELs (Ressources Éducatives Libres) et de les connecter entres elles grâce à des technologies d’IA. Cela part du constat que les RELs sont très dispersées, ce qui les rend peu visibles. Il en découle qu’un reproche souvent fait à l’éducation ouverte est la difficulté ressentie à trouver des ressources pertinentes. En plus, cette absence de visibilité nuit en particulier aux petits acteurs et donc à la diversité de provenance des ressources.
Récemment, en plus de ton contrat de doctorant, tu as été recruté au sein de la Chaire RELIA en tant qu’ingénieur. Quelles sont tes nouvelles missions en lien avec ce poste ?
Je travaille en particulier sur 2 projets : un nommé Florilège et l’autre CLARA.
Dans le projet CLARA, l’idée est d’utiliser des technologies du web sémantique pour représenter les RELs et ainsi être plus à même de les recommander, par exemple. Un des avantages du web sémantique est de pouvoir tirer profit de la structuration des données, même en cas d’informations incomplètes. Pour ce faire, on utilise des bases de connaissances, appelées ontologies, qui sont des manières de structurer la connaissance. Une des plus connues est DBpedia, basée sur l’encyclopédie Wikipédia. Dans le contexte de l’écosystème RELs, où les différents acteurs ont tous des manières différentes de référencer leurs ressources, cette approche peut s’avérer particulièrement intéressante.
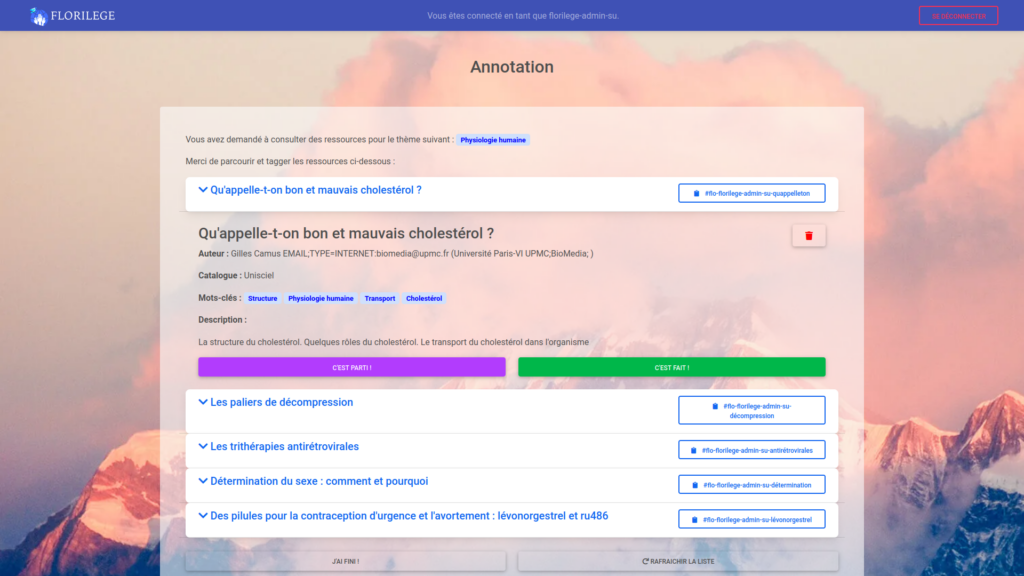
Dans le projet Florilège, l’idée est d’annoter collectivement des RELs, c’est donc une initiative de science participative. Durant le projet X5-GON, la stratégie initiale était une indexation automatique des RELs, un algorithme – appelé crawler – était chargé de fouiller le web à la recherche de RELs à indexer. En pratique, cette méthode automatique a l’avantage de permettre de récupérer rapidement un grand nombre d’URL hébergeant des RELs. Néanmoins, il est très difficile de récupérer de manière automatique des informations permettant de caractériser ces RELs : on parle de méta-données. Pourtant, ces méta-données sont souvent simples à récupérer pour un utilisateur humain, cela peut simplement être la licence, la limite de la ressource, sa nature (un exercice, un cours complet, un diaporama, etc.). L’idée de Florilège est de permettre à des utilisateurs volontaires de compléter les méta-données des ressources et ainsi de permettre un meilleur accès et une meilleure identification des RELs.
Bien sûr, à terme, les données renseignées par les annotateurs pourront permettre d’entraîner des modèles capables de les suppléer et ainsi d’aller vers des méthodes plus automatiques.
Et maintenant, où en sommes-nous ? Qu’est-il prévu, à plus ou moins long terme, concernant Florilège, CLARA ?
Pour commencer, j’espère soutenir ma thèse à la rentrée !
À court terme, nous avons fini une version alpha de Florilège et souhaitons bientôt lancer les premiers RELathons, qui seront des événements d’annotation participative des RELs, à la manière des Wikithons.
À plus long terme, nous espérons collecter suffisamment d’annotations pour pouvoir améliorer la représentation des RELs. Et partager ces nouvelles données au plus grand nombre, à la manière de ce qui a été fait dans le projet X5-GON.
Enfin, dans le projet CLARA, nous travaillons en étroite collaboration avec nos partenaires, dans le but de proposer notamment un moteur de recherche de RELs qui tirerait à la fois profit des annotations récupérées, mais permettrait aussi d’identifier les ressources pour lesquelles l’annotation est la plus urgente.
Merci Victor. Et bonne continuation !

Sauf indication contraire, l’ensemble des contenus de ce site https://chaireunescorelia.univ-nantes.fr/ est mis à disposition selon les termes de la Licence Creative Commons Attribution 4.0 International.