
La Chaire Unesco mène actuellement le projet de recherche Florilège, dont l’objectif est de permettre l’identification de REL sur le web, leur comparaison et leur évaluation par des humains. En effet, de nombreuses tâches restent complexes à effectuer de manière automatique par des machines, telles que :
- La navigation automatique sur des sites web contenant de multiples liens de navigation
- L’identification des licences qui peuvent être, soit des mentions texte de type CC BY, soit des images sous forme de logo
- L’évaluation de ces ressources, comprenant leur niveau de difficulté, leur accès, l’ordre dans lequel les consulter, la comparaison entre plusieurs ressources
- Et, enfin, la recommandation individualisée de ressource pour un utilisateur avec un profil et des objectifs pédagogiques particuliers
Pour le moment, les solutions proposées associent l’exploration automatique du web par des machines, appelés “crawlers” qui parcourent les pages web afin d’identifier des ressources et en faire remonter les données, ainsi que l’implication d’humains dans l’évaluation des ressources et la navigation complexe.
L’expérimentation menée par Bastien Masse et résumée dans cet article, avait pour objectif de tester les capacités de système de type LLM (Large Language Models), en particulier ici de Chat-GPT, pour réaliser ces mêmes tâches. Nous vous en proposons le compte rendu ci-dessous.
L’expérimentation a permis d’aboutir aux deux modèles suivants, sous la forme de “prompts” à entrer dans Chat-GPT. Ces prompts sont des ensemble de texte, sans code informatique, qui servent de base à la réponse produite par Chat-GPT. Ils sont ici utilisés pour définir le comportement que Chat-GPT doit avoir et permettre une utilisation guidée.
Le premier prompt a été conçu afin de permettre la caractérisation des ressources :
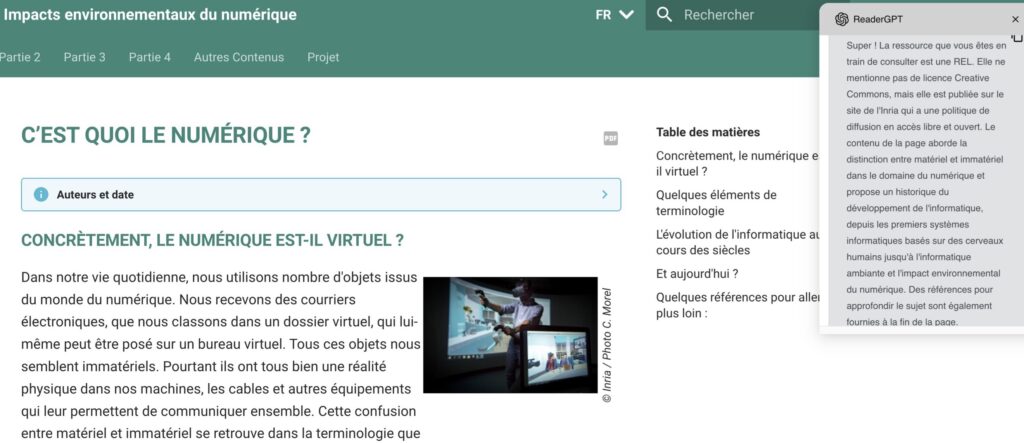
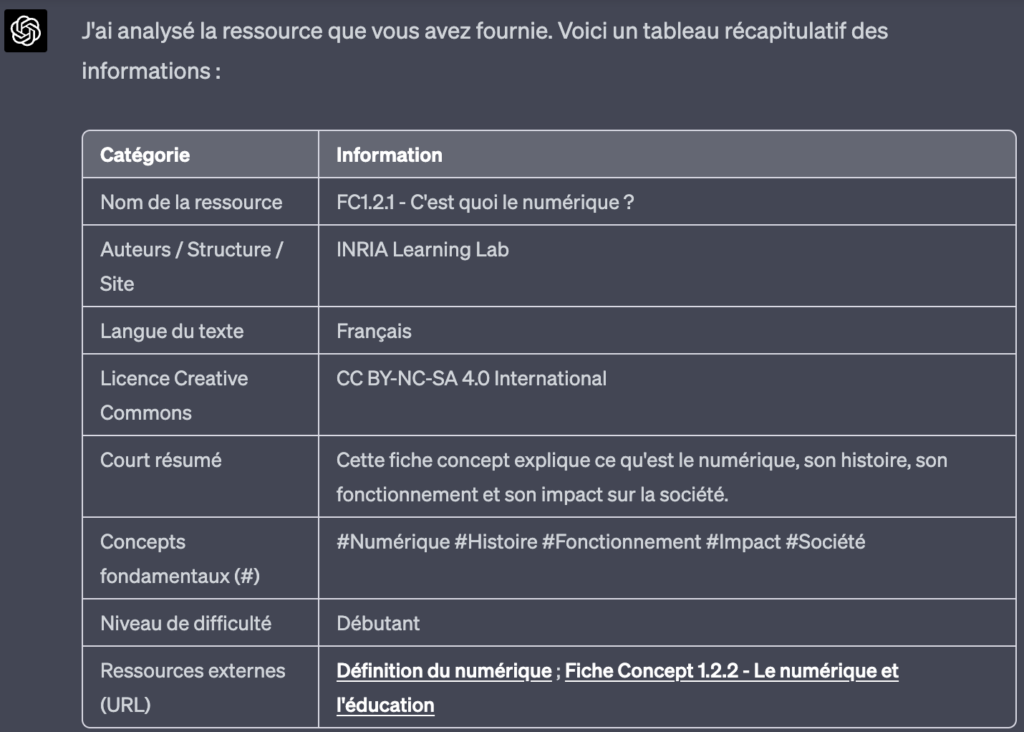
A partir d’un lien url vers une page web ou un document pdf, il propose une fiche d’identification de la ressource sous forme d’un tableau mentionnant :
- Les auteurs du document (personnes, établissement ou site)
- La langue
- La présence d’une licence Creative Commons et/ou les conditions de partage et de diffusion du document
- Les thèmes et concepts principaux abordés, sous forme de #
- Les liens et ressources externes présents dans le document
A noter qu’un prompt similaire peut être utilisé avec des plugins pour navigateur utilisant Chat-GPT afin de faire de la détection « à la volée » sur une page en cours.
Le second modèle a été créé dans un objectif d’analyse, de comparaison et de recommandation des ressources.
Il offre un accompagnement complet de l’utilisateur dans l’exploration de ses ressources, en l’interrogeant sur ses besoins et objectifs afin de permettre une recommandation individualisée.
- Le modèle vous interroge sur votre connaissance éventuelle du sujet, vos objectifs pédagogiques, le temps dont vous disposez pour étudier, vos langues et formats préférés…
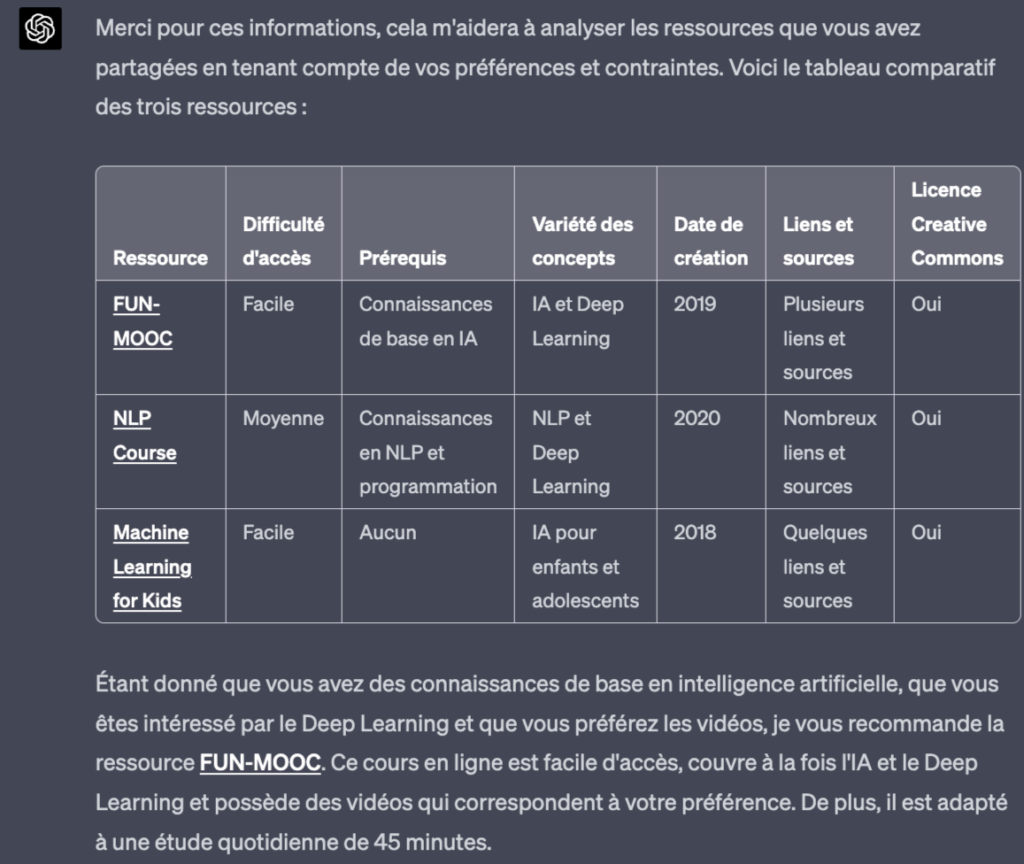
- Il est ensuite en mesure d’analyser et de comparer plusieurs ressources que vous lui donnerez sous forme d’url ou de texte
- Il vous proposera ensuite une analyse comparative des ressources sous forme de tableau et vous fera une recommandation sur la plus pertinente en fonction des préférences que vous avez fournies
- Le modèle permet également l’analyse comparative de plusieurs ressources en même temps en fonction de critères que vous décidez vous-même

Les résultats, s’ils paraissent satisfaisants au premier abord, contiennent les biais et limites habituels des systèmes de type LLM, à savoir :
- Certaines informations peuvent parfois être fausses ou inventées (par exemple avec une licence 3.0 qui se transforme en 4.0, l’absence de détection ou l’invention de licence)
- Certains liens fournis en exemple de ressources complémentaires sont inexistants
- La détection de licence ou la recommandation peuvent parfois changer d’une requête à une autre, en raison de la fonction créative aléatoire de Chat-GPT (fonction qui favorise la création de réponses différentes pour une même requête)
- Si une discussion dure trop longtemps avec l’utilisateur, Chat-GPT peut “oublier” des parties de son prompt initial
Reste que les résultats semblent suffisamment encourageants pour engager une expérimentation plus approfondie de l’utilisation des LLM dans la recherche, l’identification et dans l’évaluation des REL. Ces prompts ont été testés sur les versions 3.5 et 4.0 de Chat-GPT dans sa version web. La dernière version semble présenter moins de faux positifs mais ils sont toujours présents, l’analyse comparative est par contre beaucoup plus fine et permet certaines « déductions » telles que les conditions d’utilisation d’un contenu spécifique sur la base des règles de partage général du site source. Nous souhaitons à présent tester l’API afin de la tester avec des bases de données de REL existantes, pour l’amélioration de crawlers et pour un apprentissage spécialisé sur les licences et les ressources pédagogiques libres. Les prompts utilisés lors de cette expérimentation sont accessibles en ressource éducative libre CC-BY au lien suivant:
Lien pour télécharger les prompts
Sauf indication contraire, l’ensemble des contenus de ce site https://chaireunescorelia.univ-nantes.fr/ est mis à disposition selon les termes de la Licence Creative Commons Attribution 4.0 International.
